
The rise of Chinese AI startup DeepSeek has been nothing short of remarkable. After surpassing ChatGPT on the App Store, DeepSeek sent shockwaves to the tech world, triggering a frenzy in the market. But the attention hasn’t all been positive. DeepSeek’s website faced an attack that forced the company to suspend registrations, and some skeptics questioned whether the startup had relied on export-restricted Nvidia H100 chips rather than the H800 chips it claimed to use—raising concerns about compliance and cost efficiency.
Now, a breakthrough from researchers at the University of California, Berkeley, is challenging some of these assumptions. A team led by Ph.D. candidate Jiayi Pan has managed to replicate DeepSeek R1-Zero’s core capabilities for less than $30—less than the cost of a night out. Their research could spark a new era of small model RL revolution.
Their findings suggest that sophisticated AI reasoning doesn’t have to come with a massive price tag, potentially shifting the balance between AI research and accessibility.
Berkeley Researchers Recreate DeepSeek R1 for Just $30—A Challenge to H100 Narrative
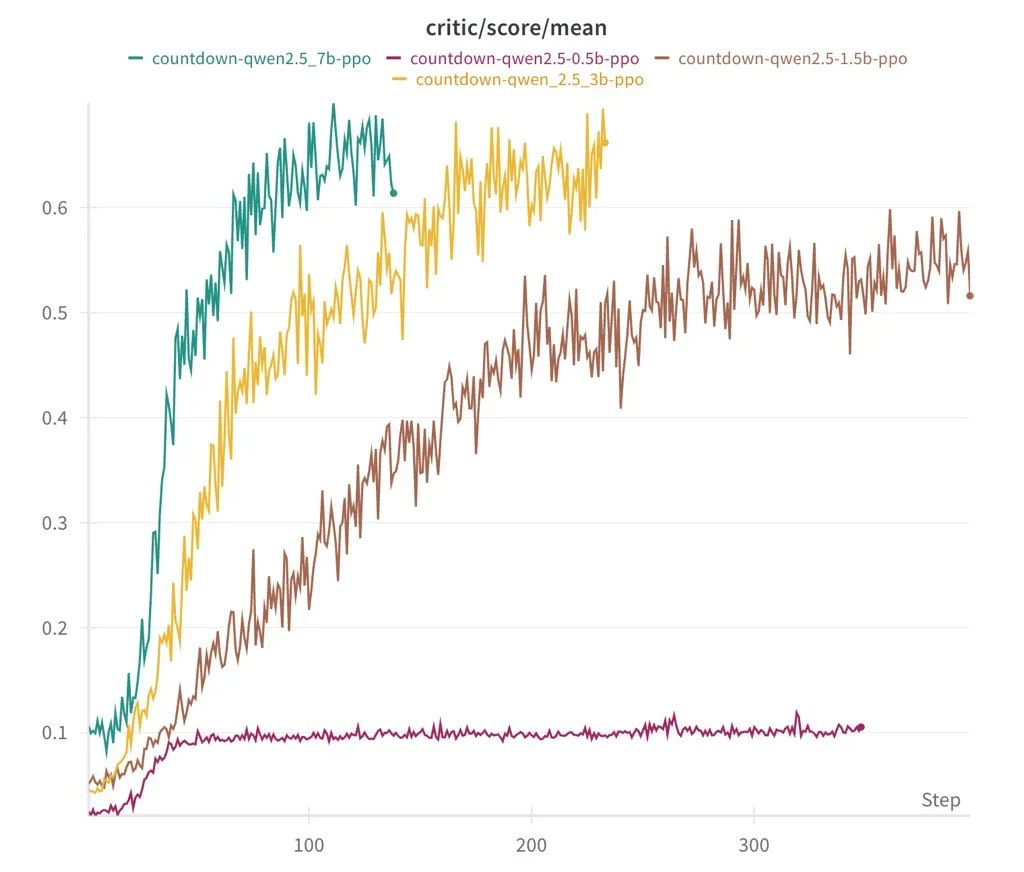
The Berkeley team says they worked with a 3-billion-parameter language model from DeepSeek, training it through reinforcement learning to develop self-verification and search abilities. The goal was to solve arithmetic-based challenges by reaching a target number—an experiment they managed to complete for just $30. By comparison, OpenAI’s o1 APIs cost $15 per million input tokens—more than 27 times the price of DeepSeek-R1, which runs at just $0.55 per million tokens. Pan sees this project as a step toward lowering the barrier to reinforcement learning scaling research, especially given its minimal cost.
But not everyone is on board. Machine learning expert Nathan Lambert questions DeepSeek’s claim that training its 671-billion-parameter model only costs $5 million. He argues that the figure likely excludes key expenses such as research personnel, infrastructure, and electricity. His estimates put DeepSeek AI’s annual operating costs somewhere between $500 million and over $1 billion. Even so, the achievement stands out—especially considering that top U.S. AI firms are pouring $10 billion a year into their AI efforts.
Breaking Down the Experiment: Small Models, Big Impact
According to Jiayi Pan’s post on Nitter, the team successfully reproduced DeepSeek R1-Zero using a small language model with 3 billion parameters. Running reinforcement learning on the Countdown game, the model developed self-verification and search strategies—key abilities in advanced AI systems.
Key takeaways from their work:
- They successfully reproduced DeepSeek R1-Zero’s methods for under $30.
- Their 1.5-billion-parameter model demonstrated advanced reasoning skills.
- Performance was on par with larger AI systems.
“We reproduced DeepSeek R1-Zero in the CountDown game, and it just works. Through RL, the 3B base LM develops self-verification and search abilities all on its own. You can experience the Ahah moment yourself for < $30,” Pan said on X.
We reproduced DeepSeek R1-Zero in the CountDown game, and it just works
Through RL, the 3B base LM develops self-verification and search abilities all on its own
You can experience the Ahah moment yourself for < $30
Code: https://t.co/B2IsN1PrXV
Here’s what we learned 🧵 pic.twitter.com/43BVYMmS8X
— Jiayi Pan (@jiayi_pirate) January 24, 2025
Reinforcement Learning Breakthrough
The researchers began with a base language model, a structured prompt, and a ground-truth reward. They then introduced reinforcement learning through Countdown, a logic-based game adapted from a British TV show. In this challenge, players must reach a target number using arithmetic operations—a setup that encourages AI models to refine their reasoning skills.
Initially, the AI produced random answers. Through trial and error, it began verifying its own responses, adjusting its approach with each iteration—mirroring how humans solve problems. Even the smallest 0.5-billion-parameter model could only make simple guesses, but once scaled to 1.5 billion and beyond, the AI started exhibiting more advanced reasoning.
“We reproduced DeepSeek R1-Zero in the CountDown game, and it just works. Through RL, the 3B base LM develops self-verification and search abilities all on its own You can experience the Ahah moment yourself for < $30https://github.com/Jiayi-Pan/TinyZero
Here’s what we learned,” Pan said in a post on Nitter
Surprising Discoveries
One of the most interesting findings was how different tasks led the model to develop distinct problem-solving techniques. In Countdown, it refined its search and verification strategies, learning to iterate and improve its answers. When tackling multiplication problems, it applied the distributive law—breaking numbers down much like humans do when solving complex calculations mentally.
Another notable finding was that the choice of reinforcement learning algorithm—whether PPO, GRPO, or PRIME—had little impact on overall performance. The results were consistent across different methods, suggesting that structured learning and model size play a greater role in shaping AI capabilities than the specific algorithm used. This challenges the notion that sophisticated AI requires vast computational resources, demonstrating that complex reasoning can emerge from efficient training techniques and well-structured models.
A key takeaway from the research was how the model adapted its problem-solving techniques based on the task at hand.
Smarter AI Through Task-Specific Learning
One of the most interesting takeaways is how the AI adapted to different challenges. For the Countdown game, the model learned search and self-verification techniques. When tested with multiplication problems, it approached them differently—using the distributive law to break down calculations before solving them step by step.
Instead of blindly guessing, the AI refined its approach over multiple iterations, verifying and revising its own answers until it landed on the correct solution. This suggests that models can evolve specialized skills depending on the task, rather than relying on a one-size-fits-all reasoning method.
A Shift in AI Accessibility
With the full project costing less than $30 and the code publicly available on GitHub, this research makes advanced AI more accessible to a wider range of developers and researchers. It challenges the notion that groundbreaking progress requires billion-dollar budgets, reinforcing the idea that smart engineering can often outpace brute-force spending.
This work reflects a vision long championed by Richard Sutton, a leading figure in reinforcement learning, who argued that simple learning frameworks can yield powerful results. The Berkeley team’s findings suggest he was right—complex AI capabilities don’t necessarily require massive-scale computing, just the right training environment.
Conclusion
As AI development accelerates, breakthroughs like this could reshape how researchers think about efficiency, cost, and accessibility. What started as an effort to understand DeepSeek’s methods may end up setting new standards for the field.
Chinese AI startup shocked the global tech industry when it rolled out DeepSeek-V3 in December 2024 at a fraction of the cost of competing AI models. The open-source model, developed in just two months for under $6 million, outperformed OpenAI and Meta’s latest AI models across multiple benchmarks. A few weeks later, on January 23, the company introduced DeepSeek-R1, a reasoning model positioned as a direct competitor to OpenAI’s o1.
While some question DeepSeek’s claim, this development nonetheless challenges the long-held belief that building sophisticated AI models requires billions of dollars and an army of Nvidia GPUs. It also raises questions about the massive $500 billion Stargate project, a venture-backed by OpenAI, Oracle, SoftBank, and MGX, aimed at setting up large-scale data centers across the U.S.
DeepSeek trained its model using about 2,000 Nvidia H800 GPUs—far fewer than the tens of thousands typically deployed by major players. By focusing on algorithmic efficiency and open-source collaboration, the company managed to achieve results comparable to OpenAI’s ChatGPT at a fraction of the cost.
The market reaction was immediate. Nvidia’s stock suffered a historic drop, sliding nearly 17% and wiping out around $600 billion in market value—the biggest single-day loss in U.S. stock market history. The shockwave forced many to rethink the need for massive AI infrastructure spending and the industry’s dependence on top-tier hardware.
Some analysts argue that DeepSeek’s success could make AI development more accessible and significantly lower costs, reshaping competition in the industry.
Can You Run AI and Large Language Models Without NVIDIA GPUs?

NVIDIA H100 Tensor Core GPU (Credit: Nvidia)
The simple is Yes, NVIDIA GPUs aren’t the only option for running AI models. While they are widely used for training and deploying complex machine-learning models, other alternatives exist. AMD GPUs, for example, offer competitive performance and are gaining traction in AI research and development.
Beyond traditional GPUs, AI models can also run on CPUs, TPUs (Tensor Processing Units), FPGAs (Field-Programmable Gate Arrays), and even custom AI accelerators designed by companies like Apple, Google, and Tesla. The choice of hardware depends on factors like model complexity, speed requirements, power consumption, and budget constraints.
For large-scale deep learning training, NVIDIA GPUs are popular due to their optimized software ecosystem, including CUDA and cuDNN, which work seamlessly with frameworks like TensorFlow and PyTorch. However, for smaller tasks, inference workloads, or energy-efficient deployments, alternatives like AMD ROCm, Intel’s AI accelerators, and Google’s TPUs can be viable options.
If you’re developing AI models, it’s worth considering the hardware that best fits your needs rather than defaulting to NVIDIA simply because it’s the most well-known choice.
Do GPUs Still Matter for AI?
DeepSeek’s breakthrough raises an important question: Do AI models really need Nvidia’s GPUs? And if not, what does this mean for companies like Nvidia, AMD, and Broadcom? The simple answer is you don’t necessarily need NVIDIA GPUs—or any GPUs—to run AI models. An example of this is Neural Magic, an AI startup that is making deep learning possible without specialized hardware
GPUs.
For years, GPUs have been the go-to choice for training deep learning models, but they might not be essential for every AI workload. The bigger question is whether GPUs are heading toward becoming as common as today’s CPUs—and whether Nvidia risks following the path of companies like Cisco, which once dominated networking before competition caught up.
There’s no simple answer. While GPUs remain critical for high-performance AI, advances in efficiency could shift the balance, making AI more accessible without the need for enormous hardware investments.
CPUs vs. GPUs: What’s the Difference?
What Is a CPU?
A CPU, or central processing unit, is the core of a computer’s operations, built to handle tasks in a step-by-step manner. It’s designed for flexibility, making it great for running operating systems, managing input and output, and handling general computing workloads. With a few powerful cores, CPUs excel at sequential processing but struggle when large numbers of calculations need to happen simultaneously. As Lifewire notes, CPUs are well-suited for tasks that require precise execution in order, but they aren’t optimized for the massive parallel processing required by modern AI models.
What Is a GPU?
A GPU, or graphics processing unit, was originally designed for rendering graphics but has become a key tool in AI development. Unlike CPUs, GPUs come packed with hundreds or thousands of smaller cores that can handle multiple calculations at once. This ability to process large amounts of data in parallel makes them particularly useful for machine learning and deep learning applications. Discussions on Reddit among AI researchers highlight how GPUs make training complex models faster and more efficient by handling vast amounts of matrix operations at the same time.
Why AI Training Relies on GPUs
Parallel Processing
Training AI models—especially deep neural networks—involves millions or even billions of calculations. GPUs are built for handling these workloads efficiently, spreading them across many cores to speed up the process. A CPU, on the other hand, would need to handle each step one at a time, leading to longer training times. With GPUs, training happens faster, allowing researchers and developers to iterate on models more quickly.
Optimized AI Frameworks
Many of today’s top machine learning libraries, including TensorFlow and PyTorch, are built to take advantage of GPU acceleration. These frameworks don’t just benefit from the hardware itself—they also come with built-in tools that streamline AI model development. This is a big reason why researchers and companies tend to invest heavily in GPU-based setups.
When a GPU Might Not Be Necessary
Inference vs. Training
While GPUs play a critical role in training AI models, they aren’t always needed for running those models in real-world applications. Once a model is trained, it can often make predictions on a CPU without significant slowdowns, especially in scenarios where speed isn’t a priority. For lightweight tasks, CPUs can be a more cost-effective and energy-efficient choice.
Early-Stage Development
If you’re working on a small-scale project or just experimenting, a high-powered GPU might not be necessary. Many cloud platforms offer pay-as-you-go access to GPUs, allowing developers to start on a CPU and upgrade as their needs grow. In some cases, small models can run on CPUs without major performance issues, though execution times may be slower.
Alternative Hardware
Beyond CPUs and GPUs, other options exist, such as Tensor Processing Units (TPUs) and specialized inference chips. TPUs, developed by Google, are optimized for specific AI workloads and can sometimes outperform GPUs. However, they come with unique setup requirements, so most developers continue to rely on GPUs for flexibility.
Cost and Energy Efficiency
GPUs are powerful, but they’re also expensive and consume a lot of energy. Companies with tight budgets or sustainability concerns may need to weigh the benefits of using GPUs versus sticking with high-performance CPUs or a hybrid approach. If your application doesn’t require large-scale parallel processing, CPUs might be a more practical choice.
The Right Hardware for the Job
Whether a GPU is necessary depends on the nature of your AI workload:
- Training Large AI Models – If you’re working with massive datasets and complex neural networks, a GPU is almost essential. The speed improvements over CPUs can be significant.
- Running Predictions – For smaller models and inference tasks, CPUs can often handle the workload without major slowdowns.
- Balancing Budget and Performance – If cost or power consumption is a concern, a mix of CPUs and GPUs might be the best approach.
The right choice comes down to your specific project needs, performance goals, and available resources. AI hardware decisions will continue to evolve, but understanding what CPUs and GPUs bring to the table will help you make the best decision for your work. Whether you start with a CPU or go all-in on GPUs, matching the hardware to your project’s demands is the key to getting the best results.
Below is a video on how you can run large language models on your own local machine.