Understand the AI landscape to choose the best model and provider for your use case
2025 State of AI Survey
Participate to receive the full survey report and win a pair of Ray-Ban Meta AI Glasses 🕶️
Highlights
Intelligence
Artificial Analysis Intelligence Index; Higher is better
68666053535150484843413836Gemini 2.5 ProPreviewo3-mini (high)DeepSeek R1DeepSeek V3(Mar' 25)GPT-4.1Llama 4MaverickGPT-4o (March2025)Claude 3.7SonnetGemini 2.0FlashLlama 4 ScoutLlama 3.3 70BMistral Large2 (Nov '24)GPT-4o mini
Speed
Output Tokens per Second; Higher is better
2422041831831251231151137673392523Gemini 2.0FlashGemini 2.5 ProPreviewo3-mini (high)GPT-4o (March2025)Llama 4 ScoutLlama 4MaverickGPT-4.1Llama 3.3 70BClaude 3.7SonnetGPT-4o miniMistral Large2 (Nov '24)DeepSeek V3(Mar' 25)DeepSeek R1
Price
USD per 1M Tokens; Lower is better
11.933.43.567.5Gemini 2.0FlashGPT-4o miniLlama 4 ScoutLlama 4MaverickDeepSeek V3(Mar' 25)Llama 3.3 70BDeepSeek R1o3-mini (high)Mistral Large2 (Nov '24)Gemini 2.5 ProPreviewGPT-4.1Claude 3.7SonnetGPT-4o (March2025)0.20.30.30.40.50.611.933.43.567.5
How do DeepSeek models compare?
Where can you get an API for DeepSeek R1?DeepSeek R1 Providers
Which models perform best in different languages?Multilingual Comparison
Who has the best Video Generation model?Video Arena
Which model is fastest with 100k token prompts?Long Context Latency
Language Model Comparison Highlights
Artificial Analysis Intelligence Index
Intelligence Index incorporates 7 evaluations: MMLU-Pro, GPQA Diamond, Humanity's Last Exam, LiveCodeBench, SciCode, AIME, MATH-500
6866605753535351515048484341383837Gemini 2.5 ProPreviewo3-mini (high)DeepSeek R1Claude 3.7SonnetThinking DeepSeek V3(Mar' 25)GPT-4.1 miniGPT-4.1Grok 3Llama 4MaverickGPT-4o (March2025)Claude 3.7SonnetGemini 2.0FlashLlama 4 ScoutGPT-4.1 nanoMistral Large2 (Nov '24)Gemma 3 27BNova Pro
+ Add model from specific provider
Artificial Analysis Intelligence Index: Combination metric covering multiple dimensions of intelligence - the simplest way to compare how smart models are. Version 2 was released in Feb '25 and includes: MMLU-Pro, GPQA Diamond, Humanity's Last Exam, LiveCodeBench, SciCode, AIME, MATH-500. See Intelligence Index methodology for further details, including a breakdown of each evaluation and how we run them.
Artificial Analysis Intelligence Index by Model Type
Intelligence Index incorporates 7 evaluations: MMLU-Pro, GPQA Diamond, Humanity's Last Exam, LiveCodeBench, SciCode, AIME, MATH-500
Reasoning Model
Non-Reasoning Model
6866605753535351515048484341383837Gemini 2.5 ProPreviewo3-mini (high)DeepSeek R1Claude 3.7SonnetThinking DeepSeek V3(Mar' 25)GPT-4.1 miniGPT-4.1Grok 3Llama 4MaverickGPT-4o (March2025)Claude 3.7SonnetGemini 2.0FlashLlama 4 ScoutGPT-4.1 nanoMistral Large2 (Nov '24)Gemma 3 27BNova Pro
+ Add model from specific provider
Artificial Analysis Intelligence Index: Combination metric covering multiple dimensions of intelligence - the simplest way to compare how smart models are. Version 2 was released in Feb '25 and includes: MMLU-Pro, GPQA Diamond, Humanity's Last Exam, LiveCodeBench, SciCode, AIME, MATH-500. See Intelligence Index methodology for further details, including a breakdown of each evaluation and how we run them.
Artificial Analysis Intelligence Index by Open Weights vs Proprietary
Intelligence Index incorporates 7 evaluations: MMLU-Pro, GPQA Diamond, Humanity's Last Exam, LiveCodeBench, SciCode, AIME, MATH-500
Proprietary
Open Weights
Open Weights (Commercial Use Restricted)
6866605753535351515048484341383837Gemini 2.5 ProPreviewo3-mini (high)DeepSeek R1Claude 3.7SonnetThinking DeepSeek V3(Mar' 25)GPT-4.1 miniGPT-4.1Grok 3Llama 4MaverickGPT-4o (March2025)Claude 3.7SonnetGemini 2.0FlashLlama 4 ScoutGPT-4.1 nanoMistral Large2 (Nov '24)Gemma 3 27BNova Pro
+ Add model from specific provider
Artificial Analysis Intelligence Index: Combination metric covering multiple dimensions of intelligence - the simplest way to compare how smart models are. Version 2 was released in Feb '25 and includes: MMLU-Pro, GPQA Diamond, Humanity's Last Exam, LiveCodeBench, SciCode, AIME, MATH-500. See Intelligence Index methodology for further details, including a breakdown of each evaluation and how we run them.
Open Weights: Indicates whether the model weights are available. Models are labelled as 'Commercial Use Restricted' if the weights are available but commercial use is limited (typically requires obtaining a paid license).
Artificial Analysis Coding Index
Represents the average of coding benchmarks in the Artificial Analysis Intelligence Index (LiveCodeBench & SciCode)
5755494444424040383836322929232217o3-mini (high)Gemini 2.5 ProPreviewDeepSeek R1GPT-4.1 miniClaude 3.7SonnetThinking GPT-4.1Grok 3GPT-4o (March2025)Claude 3.7SonnetDeepSeek V3(Mar' 25)Llama 4MaverickGemini 2.0FlashGPT-4.1 nanoMistral Large2 (Nov '24)Llama 4 ScoutNova ProGemma 3 27B
+ Add model from specific provider
Artificial Analysis Coding Index: Represents the average of coding evaluations in the Artificial Analysis Intelligence Index. Currently includes: LiveCodeBench, SciCode. See Intelligence Index methodology for further details, including a breakdown of each evaluation and how we run them.
Artificial Analysis Math Index
Represents the average of math benchmarks in the Artificial Analysis Intelligence Index (AIME 2024 & Math-500)
9392827372686764636160575654544542Gemini 2.5 ProPreviewo3-mini (high)DeepSeek R1DeepSeek V3(Mar' 25)Claude 3.7SonnetThinking GPT-4.1 miniGPT-4.1Llama 4MaverickGemini 2.0FlashGPT-4o (March2025)Grok 3Gemma 3 27BLlama 4 ScoutGPT-4.1 nanoClaude 3.7SonnetNova ProMistral Large2 (Nov '24)
+ Add model from specific provider
Artificial Analysis Math Index: Represents the average of math evaluations in the Artificial Analysis Intelligence Index. Currently includes: AIME, MATH-500. See Intelligence Index methodology for further details, including a breakdown of each evaluation and how we run them.
Intelligence Evaluations
Intelligence evaluations measured independently by Artificial Analysis; Higher is better
Results claimed by AI Lab (not yet independently verified)
MMLU-Pro (Reasoning & Knowledge)
86%84%84%82%81%81%80%80%80%80%78%78%75%70%69%67%66%Gemini 2.5 ProPreviewDeepSeek R1Claude 3.7SonnetThinking DeepSeek V3(Mar' 25)Llama 4MaverickGPT-4.1GPT-4o (March2025)Claude 3.7Sonneto3-mini (high)Grok 3GPT-4.1 miniGemini 2.0FlashLlama 4 ScoutMistral Large2 (Nov '24)Nova ProGemma 3 27BGPT-4.1 nano86%84%84%82%81%81%80%80%80%80%78%78%75%70%69%67%66%
GPQA Diamond (Scientific Reasoning)
84%77%77%73%71%69%67%67%66%66%66%66%62%59%51%50%49%43%Gemini 2.5 ProPreviewo3-mini (high)Claude 3.7SonnetThinking Llama 3.1Nemotron Ultra253B ReasoningDeepSeek R1Grok 3Llama 4MaverickGPT-4.1GPT-4.1 miniClaude 3.7SonnetGPT-4o (March2025)DeepSeek V3(Mar' 25)Gemini 2.0FlashLlama 4 ScoutGPT-4.1 nanoNova ProMistral Large2 (Nov '24)Gemma 3 27B84%77%77%73%71%69%67%67%66%66%66%66%62%59%51%50%49%43%
Humanity's Last Exam (Reasoning & Knowledge)
17.1%12.3%10.3%9.3%5.3%5.2%5.1%5.0%4.8%4.8%4.7%4.6%4.6%4.3%4.0%3.9%3.4%Gemini 2.5 ProPreviewo3-mini (high)Claude 3.7SonnetThinking DeepSeek R1Gemini 2.0FlashDeepSeek V3(Mar' 25)Grok 3GPT-4o (March2025)Llama 4MaverickClaude 3.7SonnetGemma 3 27BGPT-4.1 miniGPT-4.1Llama 4 ScoutMistral Large2 (Nov '24)GPT-4.1 nanoNova Pro17.1%12.3%10.3%9.3%5.3%5.2%5.1%5.0%4.8%4.8%4.7%4.6%4.6%4.3%4.0%3.9%3.4%
LiveCodeBench (Coding)
73%70%64%62%48%47%46%43%43%41%40%39%33%33%30%29%23%14%o3-mini (high)Gemini 2.5 ProPreviewLlama 3.1Nemotron Ultra253B ReasoningDeepSeek R1GPT-4.1 miniClaude 3.7SonnetThinking GPT-4.1GPT-4o (March2025)Grok 3DeepSeek V3(Mar' 25)Llama 4MaverickClaude 3.7SonnetGemini 2.0FlashGPT-4.1 nanoLlama 4 ScoutMistral Large2 (Nov '24)Nova ProGemma 3 27B73%70%64%62%48%47%46%43%43%41%40%39%33%33%30%29%23%14%
SciCode (Coding)
40%40%40%40%38%38%37%37%36%36%33%31%29%26%21%21%17%GPT-4.1 miniClaude 3.7SonnetThinking o3-mini (high)Gemini 2.5 ProPreviewGPT-4.1Claude 3.7SonnetGrok 3GPT-4o (March2025)DeepSeek V3(Mar' 25)DeepSeek R1Llama 4MaverickGemini 2.0FlashMistral Large2 (Nov '24)GPT-4.1 nanoGemma 3 27BNova ProLlama 4 Scout40%40%40%40%38%38%37%37%36%36%33%31%29%26%21%21%17%
HumanEval (Coding)
99%98%98%98%96%96%95%95%92%91%90%90%89%88%88%83%83%Gemini 2.5 ProPreviewClaude 3.7SonnetThinking DeepSeek R1o3-mini (high)GPT-4o (March2025)GPT-4.1GPT-4.1 miniClaude 3.7SonnetDeepSeek V3(Mar' 25)Grok 3Gemini 2.0FlashMistral Large2 (Nov '24)Gemma 3 27BLlama 4MaverickGPT-4.1 nanoNova ProLlama 4 Scout99%98%98%98%96%96%95%95%92%91%90%90%89%88%88%83%83%
MATH-500 (Quantitative Reasoning)
99%98%97%95%94%93%93%91%89%89%88%87%85%85%84%79%74%o3-mini (high)Gemini 2.5 ProPreviewDeepSeek R1Claude 3.7SonnetThinking DeepSeek V3(Mar' 25)Gemini 2.0FlashGPT-4.1 miniGPT-4.1GPT-4o (March2025)Llama 4MaverickGemma 3 27BGrok 3Claude 3.7SonnetGPT-4.1 nanoLlama 4 ScoutNova ProMistral Large2 (Nov '24)99%98%97%95%94%93%93%91%89%89%88%87%85%85%84%79%74%
AIME 2024 (Competition Math)
87%86%75%68%52%49%44%43%39%33%33%33%28%25%24%22%11%11%Gemini 2.5 ProPreviewo3-mini (high)Llama 3.1Nemotron Ultra253B ReasoningDeepSeek R1DeepSeek V3(Mar' 25)Claude 3.7SonnetThinking GPT-4.1GPT-4.1 miniLlama 4MaverickGemini 2.0FlashGrok 3GPT-4o (March2025)Llama 4 ScoutGemma 3 27BGPT-4.1 nanoClaude 3.7SonnetMistral Large2 (Nov '24)Nova Pro87%86%75%68%52%49%44%43%39%33%33%33%28%25%24%22%11%11%
Multilingual Index (Artificial Analysis)
83%83%Nova ProMistral Large2 (Nov '24)83%83%
+ Add model from specific provider
While model intelligence generally translates across use cases, specific evaluations may be more relevant for certain use cases.
Artificial Analysis Intelligence Index: Combination metric covering multiple dimensions of intelligence - the simplest way to compare how smart models are. Version 2 was released in Feb '25 and includes: MMLU-Pro, GPQA Diamond, Humanity's Last Exam, LiveCodeBench, SciCode, AIME, MATH-500. See Intelligence Index methodology for further details, including a breakdown of each evaluation and how we run them.
Intelligence vs. Price
Artificial Analysis Intelligence Index (Version 2, released Feb '25); Price: USD per 1M Tokens
Most attractive quadrant
GPT-4o (March 2025)
GPT-4.1 mini
GPT-4.1
GPT-4.1 nano
o3-mini (high)
Llama 4 Maverick
Llama 4 Scout
Gemini 2.0 Flash
Gemini 2.5 Pro Preview
Claude 3.7 Sonnet
Claude 3.7 Sonnet Thinking
Mistral Large 2 (Nov '24)
DeepSeek R1
DeepSeek V3 (Mar' 25)
Nova Pro
$1.00$2.00$3.00$4.00$5.00$6.00$7.00$8.00Price (USD per M Tokens)303540455055606570Artificial Analysis Intelligence IndexNova ProNova ProMistral Large 2 (Nov '24)Mistral Large 2 (Nov '24)GPT-4.1 nanoGPT-4.1 nanoLlama 4 ScoutLlama 4 ScoutGemini 2.0 FlashGemini 2.0 FlashClaude 3.7 SonnetClaude 3.7 SonnetLlama 4 MaverickLlama 4 MaverickGPT-4o (March 2025)GPT-4o (March 2025)GPT-4.1GPT-4.1GPT-4.1 miniGPT-4.1 miniDeepSeek V3 (Mar' 25)DeepSeek V3 (Mar' 25)Claude 3.7 Sonnet ThinkingClaude 3.7 Sonnet ThinkingDeepSeek R1DeepSeek R1o3-mini (high)o3-mini (high)Gemini 2.5 Pro PreviewGemini 2.5 Pro Preview
+ Add model from specific provider
While higher intelligence models are typically more expensive, they do not all follow the same price-quality curve.
Artificial Analysis Intelligence Index: Combination metric covering multiple dimensions of intelligence - the simplest way to compare how smart models are. Version 2 was released in Feb '25 and includes: MMLU-Pro, GPQA Diamond, Humanity's Last Exam, LiveCodeBench, SciCode, AIME, MATH-500. See Intelligence Index methodology for further details, including a breakdown of each evaluation and how we run them.
Price: Price per token, represented as USD per million Tokens. Price is a blend of Input & Output token prices (3:1 ratio).
Figures represent performance of the model's first-party API (e.g. OpenAI for o1) or the median across providers where a first-party API is not available (e.g. Meta's Llama models).
Intelligence vs. Output Speed
Artificial Analysis Intelligence Index (Version 2, released Feb '25); Output Speed: Output Tokens per Second
Most attractive quadrant
GPT-4o (March 2025)
GPT-4.1 mini
GPT-4.1
GPT-4.1 nano
o3-mini (high)
Llama 4 Maverick
Llama 4 Scout
Gemini 2.0 Flash
Gemini 2.5 Pro Preview
Claude 3.7 Sonnet
Mistral Large 2 (Nov '24)
DeepSeek R1
DeepSeek V3 (Mar' 25)
Nova Pro
406080100120140160180200220240260280300Output Speed (Output Tokens per Second)303540455055606570Artificial Analysis Intelligence IndexMistral Large 2 (Nov '24)Mistral Large 2 (Nov '24)DeepSeek V3 (Mar' 25)DeepSeek V3 (Mar' 25)DeepSeek R1DeepSeek R1Claude 3.7 SonnetClaude 3.7 SonnetNova ProNova ProGPT-4.1GPT-4.1Llama 4 ScoutLlama 4 ScoutLlama 4 MaverickLlama 4 MaverickGPT-4.1 miniGPT-4.1 miniGPT-4o (March 2025)GPT-4o (March 2025)o3-mini (high)o3-mini (high)Gemini 2.5 Pro PreviewGemini 2.5 Pro PreviewGemini 2.0 FlashGemini 2.0 FlashGPT-4.1 nanoGPT-4.1 nano
+ Add model from specific provider
Artificial Analysis Intelligence Index: Combination metric covering multiple dimensions of intelligence - the simplest way to compare how smart models are. Version 2 was released in Feb '25 and includes: MMLU-Pro, GPQA Diamond, Humanity's Last Exam, LiveCodeBench, SciCode, AIME, MATH-500. See Intelligence Index methodology for further details, including a breakdown of each evaluation and how we run them.
Output Speed: Tokens per second received while the model is generating tokens (ie. after first chunk has been received from the API for models which support streaming).
Figures represent performance of the model's first-party API (e.g. OpenAI for o1) or the median across providers where a first-party API is not available (e.g. Meta's Llama models).
Output Speed
Output Tokens per Second; Higher is better
26724220418318318212512311510576392523GPT-4.1 nanoGemini 2.0FlashGemini 2.5 ProPreviewo3-mini (high)GPT-4o (March2025)GPT-4.1 miniLlama 4 ScoutLlama 4MaverickGPT-4.1Nova ProClaude 3.7SonnetMistral Large2 (Nov '24)DeepSeek V3(Mar' 25)DeepSeek R1
+ Add model from specific provider
Output Speed: Tokens per second received while the model is generating tokens (ie. after first chunk has been received from the API for models which support streaming).
Figures represent performance of the model's first-party API (e.g. OpenAI for o1) or the median across providers where a first-party API is not available (e.g. Meta's Llama models).
Latency: Time To First Answer Token
Seconds to First Answer Token Received; Accounts for Reasoning Model 'Thinking' time
Input processing
Thinking (reasoning models, when applicable)
102.1Gemini 2.0FlashLlama 4 ScoutNova ProGPT-4o (March2025)GPT-4.1 miniLlama 4MaverickGPT-4.1Mistral Large2 (Nov '24)GPT-4.1 nanoClaude 3.7SonnetDeepSeek V3(Mar' 25)Gemini 2.5 ProPreviewo3-mini (high)DeepSeek R10.30.40.40.40.40.40.40.50.813.428.644.5105.3
+ Add model from specific provider
Time To First Answer Token: Time to first answer token received, in seconds, after API request sent. For reasoning models, this includes the 'thinking' time of the model before providing an answer. For models which do not support streaming, this represents time to receive the completion.
Pricing: Input and Output Prices
Price: USD per 1M Tokens
Input price
Output price
223351.62.1944.46810151515GPT-4.1 nanoGemini 2.0FlashLlama 4 ScoutLlama 4MaverickDeepSeek V3(Mar' 25)GPT-4.1 miniDeepSeek R1Nova Proo3-mini (high)Mistral Large2 (Nov '24)GPT-4.1Gemini 2.5 ProPreviewClaude 3.7SonnetClaude 3.7SonnetThinking GPT-4o (March2025)0.10.10.150.20.270.40.5511.1221.253350.40.40.50.821.11.62.1944.46810151515
+ Add model from specific provider
Input Price: Price per token included in the request/message sent to the API, represented as USD per million Tokens.
Figures represent performance of the model's first-party API (e.g. OpenAI for o1) or the median across providers where a first-party API is not available (e.g. Meta's Llama models).
Time to First Token Variance
Seconds to First Token Received; Results by percentile; Lower is better
Median, Other points represent 5th, 25th, 75th, 95th Percentiles respectively
GPT-4o (March2025)GPT-4.1 miniGPT-4.1GPT-4.1 nanoo3-mini (high)Llama 4MaverickLlama 4 ScoutGemini 2.0FlashGemma 3 27BGemini 2.5 ProPreviewClaude 3.7SonnetClaude 3.7SonnetThinking Mistral Large2 (Nov '24)DeepSeek R1DeepSeek V3(Mar' 25)Grok 3Nova ProLlama 3.1Nemotron Ultra253B Reasoning01020304050607080901000.420.420.430.8344.530.430.360.35028.580.9600.513.233.3900.40
+ Add model from specific provider
Latency (Time to First Token): Time to first token received, in seconds, after API request sent. For reasoning models which share reasoning tokens, this will be the first reasoning token. For models which do not support streaming, this represents time to receive the completion.
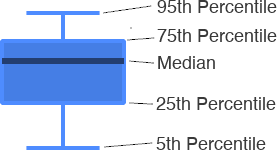
Boxplot: Shows variance of measurements
Picture of the author
API Provider Highlights: Llama 3.3 Instruct 70B
Output Speed vs. Price: Llama 3.3 Instruct 70B
Output Speed: Output Tokens per Second, Price: USD per 1M Tokens; 1,000 Input Tokens
Most attractive quadrant
Lambda Labs (FP8)
Cerebras
Hyperbolic
Amazon
Nebius Fast
Nebius Base
CentML
Azure
Fireworks
Deepinfra (Turbo, FP8)
Deepinfra
FriendliAI
Novita
Groq
SambaNova
Together.ai Turbo
kluster.ai
$0.20$0.30$0.40$0.50$0.60$0.70$0.80$0.90$1.00Price (USD per 1M Tokens)20040060080010001200140016001800200022002400Output Speed (Output Tokens per Second)DeepinfraDeepinfraDeepinfra (Turbo, FP8)Deepinfra (Turbo, FP8)Nebius BaseNebius BaseLambda Labs (FP8)Lambda Labs (FP8)kluster.aikluster.aiAzureAzureHyperbolicHyperbolicNovitaNovitaTogether.ai TurboTogether.ai TurboNebius FastNebius FastAmazonAmazonCentMLCentMLFireworksFireworksFriendliAIFriendliAIGroqGroqSambaNovaSambaNovaCerebrasCerebras
Smaller, emerging providers are offering high output speed and at competitive prices.
Price: Price per token, represented as USD per million Tokens. Price is a blend of Input & Output token prices (3:1 ratio).
Output Speed: Tokens per second received while the model is generating tokens (ie. after first chunk has been received from the API for models which support streaming).
Median: Figures represent median (P50) measurement over the past 72 hours to reflect sustained changes in performance.
Notes: Llama 3.3 70B, Cerebras: 33k context, Llama 3.3 70B, Novita: 128k context
Pricing (Input and Output Prices): Llama 3.3 Instruct 70B
Price: USD per 1M Tokens; Lower is better; 1,000 Input Tokens
Input price
Output price
0.120.130.130.230.390.40.250.50.60.590.70.710.710.880.60.90.850.30.40.40.40.390.40.750.50.60.790.70.710.710.881.20.91.2Lambda Labs(FP8)Nebius BaseDeepinfra(Turbo, FP8)DeepinfraNovitaHyperbolicNebius FastCentMLFriendliAIGroqkluster.aiAmazonAzureTogether.aiTurboSambaNovaFireworksCerebras0.120.130.130.230.390.40.250.50.60.590.70.710.710.880.60.90.850.30.40.40.40.390.40.750.50.60.790.70.710.710.881.20.91.2
The relative importance of input vs. output token prices varies by use case. E.g. Generation tasks are typically more input token weighted while document-focused tasks (e.g. RAG) are more output token weighted.
Input Price: Price per token included in the request/message sent to the API, represented as USD per million Tokens.
Output Price: Price per token generated by the model (received from the API), represented as USD per million Tokens.
Notes: Llama 3.3 70B, Cerebras: 33k context, Llama 3.3 70B, Novita: 128k context
Output Speed: Llama 3.3 Instruct 70B
Output Speed: Output Tokens per Second; 1,000 Input Tokens
2327455353184176CerebrasSambaNovaGroqFriendliAIFireworksCentMLAmazonNebius FastTogether.aiTurboNovitaHyperbolicAzurekluster.aiLambda Labs(FP8)Nebius BaseDeepinfra(Turbo, FP8)Deepinfra1841761431381341268079484439363228
Output Speed: Tokens per second received while the model is generating tokens (ie. after first chunk has been received from the API for models which support streaming).
Figures represent performance of the model's first-party API (e.g. OpenAI for o1) or the median across providers where a first-party API is not available (e.g. Meta's Llama models).
Notes: Llama 3.3 70B, Cerebras: 33k context, Llama 3.3 70B, Novita: 128k context
Output Speed, Over Time: Llama 3.3 Instruct 70B
Output Tokens per Second; Higher is better; 1,000 Input Tokens
Lambda Labs (FP8)
Cerebras
Hyperbolic
Amazon
Nebius Fast
Nebius Base
CentML
Azure
Fireworks
Deepinfra (Turbo, FP8)
Deepinfra
FriendliAI
Novita
Groq
SambaNova
Together.ai Turbo
kluster.ai
Jan 19Jan 26Feb 02Feb 09Feb 16Feb 23Mar 02Mar 09Mar 16Mar 23Mar 30Apr 06Apr 13020040060080010001200140016001800200022002400260028003000
Smaller, emerging providers offer high output speed, though precise speeds delivered vary day-to-day.
Output Speed: Tokens per second received while the model is generating tokens (ie. after first chunk has been received from the API for models which support streaming).
Over time measurement: Median measurement per day, based on 8 measurements each day at different times. Labels represent start of week's measurements.
Notes: Llama 3.3 70B, Cerebras: 33k context, Llama 3.3 70B, Novita: 128k context
See more information on any of our supported models
Model Name | Creator | License | Context Window | Further analysis |
Footer
Key Links
- Compare Language Models
- Language Models Leaderboard
- Language Model API Leaderboard
- Image Arena
- Video Arena
- Speech Arena